")
為降低AI模型取得繁體中文資料的難度,數發部研擬促進資料創新利用發展條例草案,希望先由政府開放結構及非結構化資料,如施政計畫等,並鼓勵民間捐贈資料;此外,也規畫建立臺灣主權AI訓練語料庫,供TAIDE等國內模型開發使用,並希望促成國外語言模型採用。(圖片來源/數發部)
「每個國家都要有自己生產智慧的能力」,去年2月,Nvidia執行長黃仁勳在杜拜舉行的全球政府高峰會上說,黃仁勳猶如傳教士一般,向各國政府代表喊話應該積極投入發展主權AI,特別是運用自己的語言、文化資料來發展各國自己的大語言模型。
Nvidia將主權AI定義為一個國家利用自己的基礎建設、資料、人才和商業網路來發展人工智慧的能力。
換言之,AI技術將在未來帶動社會各方面創新,不能僅有科技業者掌握AI技術發展,國家也應該主動發展主權AI,以自身的語言資料、自有的算力基礎建設、人力、產業發展自主可控的AI技術及應用。
目前有不少國家投入發展主權AI,例如新加坡政府以華語、英語、緬甸語、菲律賓語、高棉語、寮語、馬來語等11種東南亞地區使用的語言資料,建置SEA-LION大型語言模型,日本、韓國也宣布投入經費,政府與民間合作建置大型算力資源,臺灣在這波主權AI中沒有缺席。
「每個國家都非常強調主權AI,因為不可能只靠幾家大公司來服務全世界,所以一定要有主權AI,算力、資料、模型都有自主權,才是真正的主權AI」,國網中心主任張朝亮堅定地說。
臺灣如何發展主權AI
主權AI如此重要,但臺灣要發展什麼樣的主權AI?
數發部部長黃彥男在一場建構AI產業生態系的活動中表示,由於中文語料多為簡體中文,繁體中文資料相對較少,國外開源大語言模型多採用簡體中文資料訓練,AI的價值判斷傾向對岸,臺灣發展主權AI希望以在地繁中資料建立本地的模型。
至於如何著手推動主權AI,國科會說明,建構主權AI的重點在維持符合我國主權、價值觀,以及包含繁中資料在內的多元價值;國科會正積極推動我國主權性的AI技術發展,例如TAIDE,完備AI模型發展所需要的算力、資料、算法。對於訓練資料和算力資源不足的問題,政府將完善訓練及微調AI模型所需的資料、算法和算力生態系,以減少對外部不透明技術的依賴,降低潛在風險,確保AI模型的自主性、安全性與社會政治完整性。
國科會表示,我國發展主權AI的政策,來自行政院「智慧國家方案(2017年-2025年)」框架下,透過跨部會推動各面向重要數位政策,積極發展主權AI。在這個大框架下,近一步推動「臺灣AI行動計畫2.0」(2023到2026年),由各部會在技術、治理、基礎環境、人才各方面著手推動我國AI發展。
然而在當時並沒有明確說明主權AI要做什麼,而是偏向制定產業政策,提升我國數位基礎建設,AI應用和相關技術研發驅動臺灣向智慧國家發展,直到ChatGPT興起的生成式AI浪潮,進一步帶動科技業者投入大型語言模型發展。
第一步先發展臺灣文化及價值觀的TAIDE模型
在大語言模型快速發展下,訓練語言模型的語料大大影響生成式AI隱念的價值觀點,國科會為鞏固臺灣的AI主權及價值觀,在2023年開始推動可信任AI對話引擎TAIDE計畫,希望以國際的開源大語言模型為基礎,結合臺灣的繁體中文資料,在當時尚未有繁中資料訓練的LLM,搶先打造臺灣在地特色的基礎模型,並釋出供外界使用。
作為臺灣鞏固主權AI的策略,國科會以2億元經費推動TAIDE,集結國網中心、中研院、學校老師學生等專業人才組成團隊,在當時缺乏授權繁中資料下,團隊辛苦取得資料授權,模型開發初期使用台灣杉二號算力,後來採購9臺DGX H100主機,以72片GPU的4.8PF算力,專用於TAIDE模型開發使用。
2024年該計畫展現初步成果,發表基於Llama 2開源模型,搭配取得授權的文本資料打造的TAIDE-LX-7B模型,強調在中英翻譯、寫信、寫文章、摘要等已有不錯的表現。去年再釋出基於Llama 3的TAIDE 8B模型,直到今年2月才釋出基於Llama 3.1的8B模型。TAIDE模型釋出,迄今下載已超過18萬次,目前尚未看到實際應用的案例。
TAIDE從過去模型快速更新,到久久才更新模型, TAIDE模型發展策略出現新的調整。
目前擔任TAIDE模型鑄造組顧問的中研院資科所副研究員黃瀚萱直言,TAIDE從早期率先推出繁中在地化語言模型,過去兩年國內已有多個繁中語言模型,例如聯發科、台智雲等團隊釋出繁中模型,加上現在國際開源模型在繁中資料的處理能力也有不錯的表現,外界對繁中模型的選擇性增加,未來TAIDE模型降低更新頻率,選擇具有重要特色的開源模型版本釋出新模型,同時也會以多元價值資料訓練模型,強調符合臺灣在地多元價值的特色,以和其他繁中模型作區別。
儘管TAIDE計畫推動至今進入第三年,國網中心今年開始承接TAIDE計畫,為期四年,第一年經費為1.4億元,但是TAIDE模型發展策略的調整,也反映TAIDE計畫可用資源減少,特別是原先TAIDE模型使用的9臺H100主機,從專用的算力資源被轉為更大的算力資源,使得TAIDE計畫需和其他科研計畫共用算力,可使用的共用算力資源可能比原來的專用算力更少。
另一個TAIDE計畫發展的挑戰是取得繁中資料授權不易,由於缺乏繁體中文資料,難以蒐集到大量的資料投入模型訓練,因此TAIDE目前並沒有釋出更大參數規模的版本,參數量較大的13B、7B參數版本僅作為內部學研使用。
國科會指出,TAIDE模型釋出之前需經過反覆優化、參數調校,確保模型在隱私保護、可靠及準確性,經過測試及評估後才會釋出新版本;未來TAIDE計畫將持續蒐集更多繁中資料,增加資料的多元性,同時擴展算力資源,以加速模型的訓練,未來將朝多模態、推理能力發展。
TAIDE從早期偏重模型開發,未來重心將轉向拓展應用,例如從通用的基礎模型,以專業領域資料發展特定的應用,例如與政府機關合作,以公文資料強化公文輔助撰寫能力的G-TAIDE,目前已與一些部會單位進行測試。另外,先前TAIDE與大學合作,開發教育學習、醫療方面的應用。日前國科會主委吳誠文指出,為使TAIDE模型發揮更大效益,將督促國網中心,今年底與產業界合作,開發運用TAIDE模型的應用App供民眾使用。
5年擴建公共算力,目標提升30倍
政府推動主權AI,從使用在地繁中資料發展TAIDE基礎模型開始,因模型訓練需要大量算力,後來採購H100 GPU作為模型訓練的專用算力,也反映出發展主權AI需要大量的自主算力作為基礎建設。
目前各國推動主權AI,其中一項策略就是提升各國算力資源,以避免受到國外商業化算力服務的侷限,以自主算力作為發展主權AI的基礎建設,配合國家、本地產業的需要發展AI技術。
臺灣也不落人後,積極擴大國內的算力資源,例如晶創臺灣方案(2024到2033年),政府以10年投入3千億元,運用臺灣在半導體晶片製造與封測的優勢,結合生成式AI等技術發展創新應用,奠定未來十年的科技競爭力。在這項計畫中,國網中心在2024年底完成新一代超級電腦建置,命名為晶創主機Nano 5,該主機採用Nvidia H100 GPU,總算力達到16PFlops,以提升國內人工智慧模型訓練及科學模擬運算效率。未來晶創臺灣方案持續挹注經費下,預期將擴大算力至200PF。
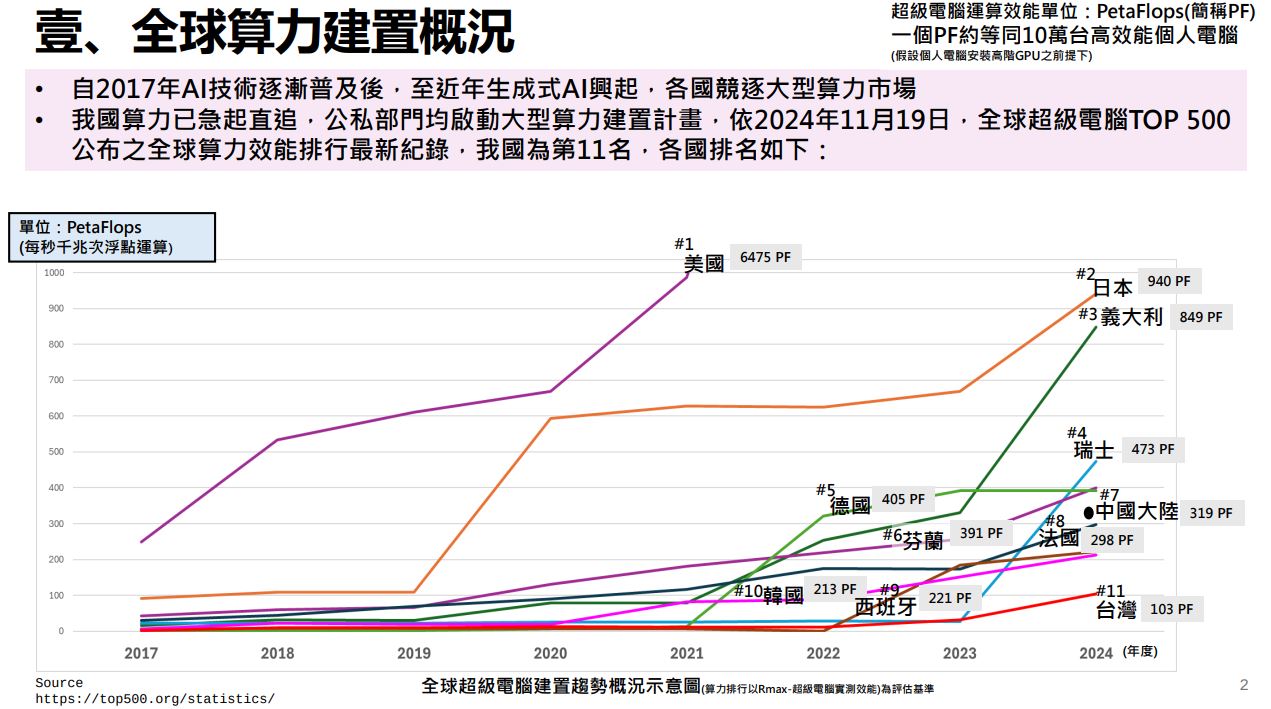
根據去年11月全球500大超級電腦排名,統計各國超級電腦算力發展趨勢,臺灣的超級電腦合計總算力為103PF,在各國中排名第11名,落後於韓國的213PF、中國的319PF,以及日本的940PF。(圖片來源/國科會)
另一項政府推動的大南方新矽谷方案,以南部地區建置半導體產業鏈,並將在臺南沙崙地區發展AI產業生態,分別從擴建算力、引入人才、鏈結場域、擴展應用四個方面推動,大南方新矽谷也規畫籌建AI超級電腦及雲端資料中心,未來再增加280PF的算力。
在晶創臺灣、大南方新矽谷兩大方案推動下,國科會預期國網中心建置的公共算力資源,將從2024年晶創主機Nano 5的16PF,到2029年達到480PF,等於5年成長30倍的算力資源,如果再加上民間因應AI擴建的私部門算力資源,國科會預估,合計超過1,600PF,政府準備建立公私算力聯盟,讓算力資源發揮效益。
國網中心負責建置超級電腦來擴建政府算力,以公共算力為基礎,今年也會建置一站式的生成式AI開發雲端服務平臺,由國網中心提供技術支援,協助新創、資服業者運用超級電腦的算力資源、開發工具、開源LLM模型,測試開發AI模型及應用。配合大南方新矽谷方案,國網中心準備在南科、沙崙兩地建立雲端資料中心,供超級電腦進駐,同時儲存巨量資料、雲端服務的基礎。
建立臺灣主權AI訓練語料庫
有鑑於TAIDE計畫取得繁中資料取得授權並不容易,高品質的繁中開放資料獲得不易,數發部為降低資料取得成本,研擬促進資料創新利用發展條例(草案),提交給行政院審議。
促進資料創新利用發展條例草案主要以非個資的資料為主,包括判別式AI訓練需要的結構化資料,以及用於生成式AI訓練的非結構化語意資料。數發部解釋發展條例立法目的為鼓勵公部門開放資料供AI研究,以及政府開放資料可以不收費,以及公務人員開放資料免責條件,政府機關可設立資料創新實驗環境。
此外,數發部也規畫建置臺灣主權AI訓練語料庫,以高品質、繁中、臺灣觀點的語料供國內包括TAIDE模型開發使用,並希望被國外開源LLM模型採用。
建置臺灣主權AI訓練語料庫的目的是降低國內外LLM取得訓練資料的成本,因此免費提供資料,鼓勵LLM使用來自臺灣的訓練資料,並且減少AI業者和內容擁有者間的著作權糾紛。
按照數發部的規畫,主權AI訓練語料庫的資料來源,包括政府擁有著作權的非機密性文件,例如政府機關的施政計畫、施政報告、研究報告、政府出版品,另一部分是民間的著作權內容,鼓勵民間捐贈的散文、小說、論文、新詩、傳記等等。
數發部指出,目前國外LLM大型語言模型在訓練資料,因著作權等種種問題,缺乏臺灣觀點的資料,主要使用簡體中文資料,因此訓練出的模型缺乏臺灣觀點,建立臺灣主權AI訓練語料庫,即是希望透過降低LLM使用臺灣語料成本,不只臺灣自主發展的LLM模型,藉此降低臺灣繁中資料取得成本,吸引國外大型語言模型採用。
扶植AI產業發展,促使AI落地各產業加速轉型
各國發展主權AI,除了擴大算力基礎建設,用於發展主權AI技術外,也以算力資源、資料開放、釋出模型,來扶植AI產業發展,以及相關人才,我國也希望建立AI有利的發展環境,培養AI產業發展,讓新創、資服業者開發AI應用,讓AI深入各產業加速轉型。
數發部數產署去年建立GPU算力池,以32片Nvidia H100及8片AMD MI300X,提供1.58PF算力資源,開放軟體、新創業者申請免費使用,供業者開發驗證AI技術。
數產署也計畫和軟體業者合作,透過舉辦Demo Day或需求媒合會,讓軟體或AI業者展示根據產業需求開發的AI工具服務,藉由工具服務讓中小型企業也能導入AI加速轉型。
由於新創或軟體業者可能缺乏資金的支持,數發部已和國發會合作,以100億元為期10年,與民間創投業者聯手共同投資具有潛力的AI業者,或是還未上市櫃的數位經濟領域公司。
在生成式AI引發各界關注,帶動AI應用走入政府及民間產業、民眾個人,政府也開始制定AI相關法規,因應公務機關使用生成式AI,國科會先提出公務機關使用生成式AI參考指引,作為公務機關使用生成式AI的指引,在今年,數發部進一步提出參考指引,輔導公務機關在公務及服務上運用AI。
2024年國科會參考其他國家及歐盟的AI相關立法,研擬我國的人工智慧基本法,去年公告研擬的人工智慧基本法草案,揭示永續發展、人類自主、隱私保護、資安與安全、透明可解釋、公平不歧視及問責等7大基本原則,該草案送交行政院審議,近期傳出將由數發部增加AI風險分類框架,從風險分類來管理AI的發展,行政院正在盤點各部會相關法規調整及配套措施。
日本、韓國也加速發展主權AI
不只臺灣,同處亞洲地區鄰近地理位置的日本及韓國,也各自提出國家AI戰略,加速各自的主權AI發展。
以日本為例,日本政府今年2月通過AI法案,與歐盟AI Act相似,採取風險管理的框架,來引導民間企業發展AI往正向發展,避免帶來的負面風險。
在擴建算力策略上,不同於臺灣建置國家級超級電腦為主,日本政府出資補助業者採購GPU,補助KDDI、軟銀、Sakura等業者採購GPU提高算力資源,透過補助企業降低他們的資本支出,達到降低算力成本,希望以此促使業者提供GPU算力服務收費。
結合大型的GPU算力資源、降低企業的算力使用成本,帶動日本業者發展LLM模型,例如軟銀旗下的SB Intuitions即於2024年先開發3,900億億參數規模的日語LLM,對外提供服務,未來開發1兆參數的LLM。
在資料方面,日本為促成AI的有利發展,日本文化廳發布「人工智慧著作權檢核清單和指引」,明定不同身分的AI利害關係人,在AI開發前後如何避免著作權侵權風險,在成為AI大國的目標下,在著作權法賦予AI訓練資料合法的重製,但也明確界定侵權的界線,在AI發展和資料的著作權保護間建立平衡點。
韓國政府立下成為AI前三大強國的目標,今年1月國會通過AI基本法,通過規範AI來建立外界的信賴基礎,並提高國家AI競爭力。韓國也設立國家AI安全委員會,專門審議AI政策及風險規範,由科學技術情報通信部(MSIT)負責統設立AI政策中心,每三年制定AI基本計畫。
儘管目前韓國在全球500大超級電腦排名上,國家算力排名前十名,但該國仍意識到算力資源不足,積極提高國家算力資源,該國政府計畫於2030年建置國家級AI運算中心,在此之前,先由政府與民間企業合作,採購1萬片GPU建置大型算力資源,逐年再增加GPU數量,2030年將算力提升至2EF以上。
韓國政府也將結合自有的GPU算力、資金打造韓國版LLM,並且加速韓國AI產業的發展。至於資料使用上,韓國政府宣示將放寬先前因隱私保護而限制的非結構化公共資料使用,並且提高高品質工業資料的可用性。
臺灣、日本、韓國同處亞洲,各自建置國內大型算力、開放資料運用、發展在地語言模型,來推動國家主權AI,同時利用大型算力、資料治理及技術,引導國內AI產業發展,進而帶動創新。
臺日韓三國主權AI策略比一比
算力
臺 灣 晶創臺灣方案、大南方新矽谷兩大方案,推動未來5年國家算力至480PF。
日 本 採取公私合作,由日本政府補助業者購買GPU擴大算力資源,藉此降低算力服務成本,日本政府補助軟銀、KDDI、Sakura等建置GPU算力。2028年達到日本國內AI算力60EF(1EF=1,000PF)的目標。
韓 國 先由政府與民間合作建置1萬片GPU,建置600PF算力。將於2030年完成國家級AI運算中心,GPU算力提升至2EF以上。
資料治理
臺 灣 數發部正在研擬「促進資料創新利用發展條例(草案)」,鼓勵政府機關帶頭開放資料,並鼓勵民間捐贈資料。今年數發部還將建置臺灣主權AI訓練語料庫。
日 本 2024年日本文化廳提出「人工智慧著作權檢核清單和指引」,規定AI開發、提供、使用及一般人不同身分的資料著作權風險。在著作權法中賦予AI訓練資料合法重製,以及可能侵害著作權的情形,維持AI訓練及著作權保護兩者間的平衡。
韓 國 韓國政府希望提高資料可用性、可訪問性。放寬先前因隱私而受限制的非結構化公共數據的訪問權限,並提高高品質工業製造數據的可用性。
主權模型
臺 灣 國科會於2023年推動可信任AI對話引擎TAIDE計畫,以開源模型為基礎,結合繁中資料,打造具有臺灣意識、本土價值觀的基礎模型,以供外界運用。近期釋出基於Llama 3.1的8B模型。
日 本 日本政府補助軟銀等企業購買GPU,軟銀子公司SB Intuitions利用算力研發日語專用的LLM,先在2024年度內完成3,900億參數的LLM,並研發1兆參數的LLM,提供相關服務。
韓 國 韓國政府將投入資金、GPU,並集結一支團隊打造韓國的LLM。
配套法規
臺 灣 國科會研擬人工智慧基本法,去年先預告草案,規定我國發展AI技術的隱私保護、問責等7項基本原則,數發部可能研擬風險分類,行政院仍在研擬中。
日 本 今年2月日本政府通過AI法案,促進人工智慧的開發和利用,並規定濫用之風險。
韓 國 2025年1月韓國國會通過AI基本法,號稱歐盟AI法案後第二個推出AI法規的國家。透過規範AI建立信賴基礎,並提高國家AI競爭力。設立國家AI安全委員會負責審議AI政策及風險規範事項,並由科學技術情報通信部(MSIT)負責設立AI政策中心,每三年制定AI基本計畫。
產業發展
臺 灣 1. 為加速產業的AI轉型,數發部從算力、資金、資料等面向扶植新創及資服業者建立AI產業生態,再由AI產業化帶動產業AI落地。
2. 民間也擴建算力資源,發展本土LLM,例如聯發科、Project TAME、福爾摩沙大模型等等。
日 本 日本政府與OpenAI合作,OpenAI推出專為日語使用者設計的GPT-4 Turbo模型;日本企業開發語言模型,例如NTT開發小語言模型tsuzumi,Line Yahoo推出Japanese-large-lm模型。
韓 國 1. 韓國政府推動製造業的AI應用。2024年投入超過1,000億韓元(約新臺幣23億元),共200項AI自主製造專案,2030年將AI自主製造普及率從目前9%提升至30%以上,並使製造生產力提高20%以上。
2. 韓國大型企業如SK電信在2023年發表首個韓國LLM模型。
人才
臺 灣 由教育部、數發部、國科會等跨部會合作,在學校教育、科學研究、產業領域培養需要的AI人才。
日 本 日本政府將和地方政府、私部門合作,確保和培訓人力資源,並將制定政策促進AI教育。
韓 國 1. 建立AI人才資料庫,以追蹤國家AI研發計畫人員就業流動狀況,助制定AI人才政策,促進產學結合。
2. MSIT也利用大數據分析,來掌握科技人才需求,並追蹤理工碩博士發展,建立12項國家戰略技術領域人才地圖,以強化追蹤產學人才供需。
資料來源:iThome整理,2025年3月